Авторы всех пожеланий в чате получат специальную марку "Меценат конкурса"
ПРИЗ КАЖДОМУ! / 100 руб.
ВСЕМ ДЕНЕГ! / 100 руб.
Салам от меня всем / 100 руб.
Желаю всем удачки))) / 100 руб.
дерзайте / 100 руб.
удачи всем! / 100 руб.
Ау? Где все? Ушли писать рассказы из детства? / 100 руб.
УДАЧИ! / 100 руб.
ВСЕМ! / 100 руб.
Творцам - витиеватостей, читателям - открытий,
А всем удач, успехов и красот! ((: ...Творцам - витиеватостей, читателям - открытий, А всем удач, успехов и красот! ((: / 100 руб.
Вот так: 350 знаков для описания парфюма, из них 70 "Carolina Herrera 212 On Ice Men 2006" и "Каролина Эрера 212 Он Айс Мэн 2006". Название товара менять нельзя. Получаем 20% копипаста. Что тут плохого? p.s. ну это всё особенности каждого заказа.
Здравствуйте. Сергей, простите что возвращаюсь к вопросу. Я правильно понял, что ключевые слова, которые повторяются в других документах и из-за которых падает уникальность, не должны влиять на решение ВМа об отказе на основании низкой уникальности текста?
Требования по уникальности повышаться не могут. Уникальность либо есть, либо ее нет. Если она есть, то текст уникальный. Если ее нет, то тогда уж появляются всякие критерии этой неуникальности.
Пишите уникальные тексты и никакие требования по НЕуникальности вас не коснутся.
Что касается платы за труд. У вас средняя стоимость за тысячу - 0.60 у.е. А у топ-авторов в 5 раз больше. Выводы, надеюсь, сможете сделать самостоятельно.
Вы прекрасно понимаете, что дефолтные настройки "шингл/фраза 5/6" и "шингл/фраза 4/4" не одно и то же. Раньше если заказчик хотел, чтобы уникальность текста составляла 95% с настройками "шингл/фраза 4/4", то ему это надо было оговаривать в условиях задания, а дополнительные требования как бы подразумевают повышение оплаты. Сейчас же этого не нужно, поскольку такие настройки уже стоят по молчанию. Следовательно, никаких ужесточенных требований заказчик не предъявляет, а значит и платить можно по минимуму.
Что касается топ-авторов.. видимо это копирайтеры, а я рерайтер. На их гонорары я не претендую, но вот ожидать оплату в размере 0,9-1$ за 1000 символов за тексты с уникальностью 95% с настройками "шингл/фраза 4/4", мне кажется, более чем справедливо.
кстати вы ошибаетесь. можно писать текст исключительно из головы. без источников. и получится может уникальность и 85 например. а если технический текст и термины, то еще хуже. Часто страдают формулировки предложений в угоду уникальности. я вот уже ровно 3 часа не могу сео-рерайт с 1 источником конкретным довести до 95%. и сомневаюсь в том, что это возможно.
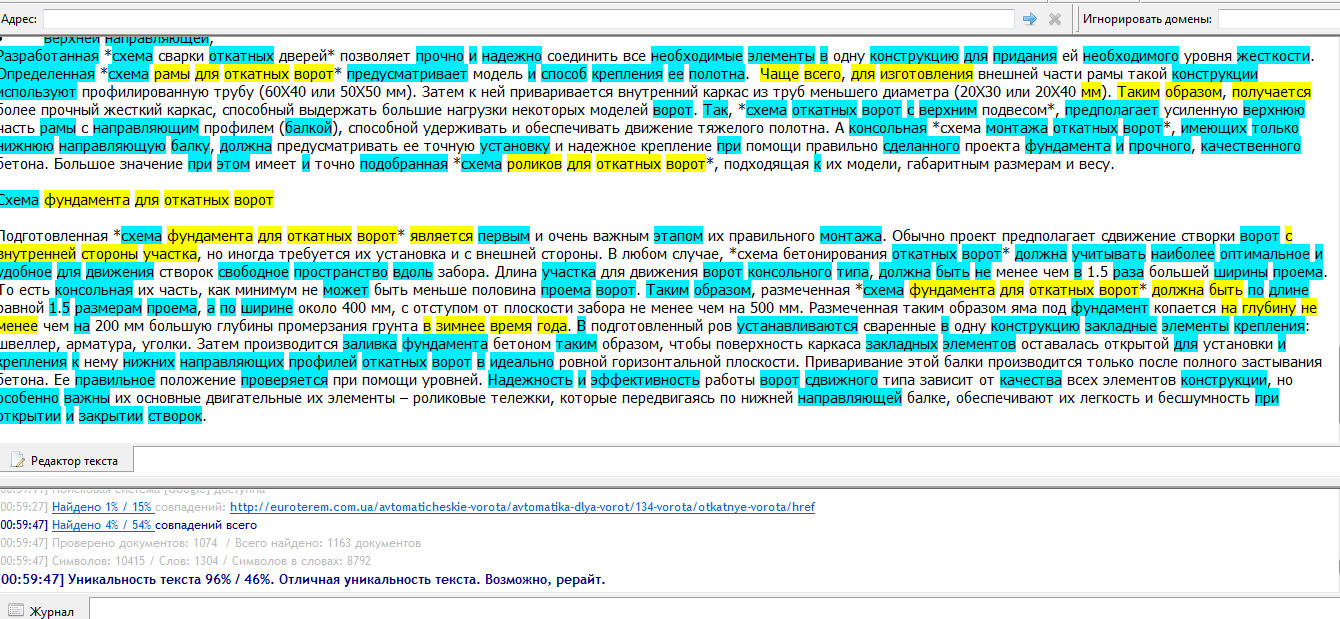
Объясните пожалуйста почему один и тот же текст АП выводит разные значения : 1) Уникальность текста 90% / 47%. Низкая уникальность текста. Возможно, рерайт. 2) Уникальность текста 95% / 100%. Хорошая уникальность текста. В 1м случае выделяет синим и желтым, а во втором только только желтым. Проверяла 1 и тот же текст ничего не меняя.
- уникальность [95 .. 100]% - очень хорошо, ибо [0 .. 5]% совпадений; - уникальность [90 .. 94]% - хорошо, ибо [6 .. 10]% совпадений; - уникальность [80 .. 89]% - удовлетворительно, ибо [11 .. 20]% совпадений; - уникальность [0 .. 79]% - не уникально, ибо [21 .. 100]% совпадений.
-- Комментарии:
- по каждой странице выводится процент СОВПАДЕНИЙ; - в завершении проверки выводится общий процент СОВПАДЕНИЙ; - затем, в итоговом отчете, выводится общий процент УНИКАЛЬНОСТИ; - общий процент совпадений считается как полное пересечение совпадений на всех найденных страницах, так, как-будто все эти совпадения на одной странице; - предположение о рерайте делается в том случае, если состав слов совпадает на 30% и выше; - красным подсвечиваются совпадения УДОВЛЕТВОРИТЕЛЬНО и НЕ УНИКАЛЬНО, и предполагаемый рерайт.
-- Корректировка протоколы работы:
- добавлена информация о настройках проверки - устранение ошибки работы панели прогресса
Да у меня только 25 выполненных работ и одна проданная статья. Но почему-то до обновленния програмы я умудрядся писать статьи с уникальностью 95 - 100 %, а после обновленния внезапно разучилься.
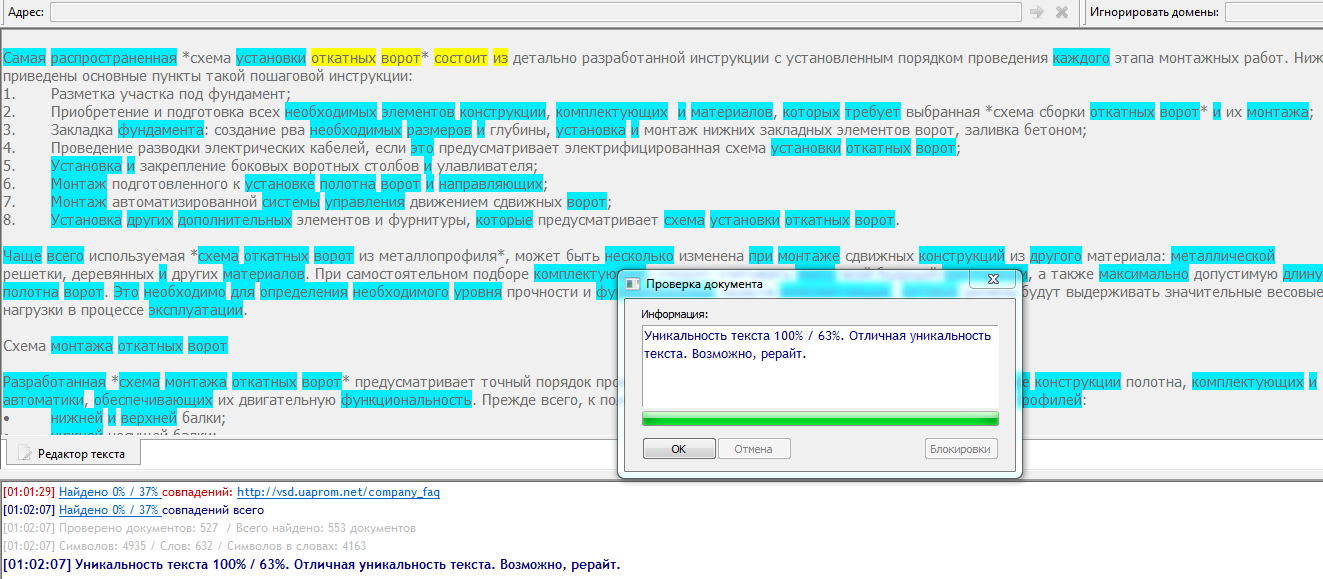
Сегодня заметила интересную закономерность новой версии АП. При проверке текста 10 кзн получила 96% уникальности и 46% возможного рерайта. После того как разбила текст на две части по 5 кзн, получилось 100/63 и 96/100/. Таким образом получается, что чем меньше текст, тем меньшее количество совпадений часто встречающихся в сети выражений и технических терминов высвечивается в результате проверки по проценту возможного рерайта.
Наличие рерайта - может быть по разному. В вашем случае, по второму фрагменту нашелся источник рерайта, поэтому в первом фрагменте рерайта не найдено. Все вполне логично.
Сергей, наверно поздно по времени. но хочу спросить следующее. При проверке текстов часто выходит например 100/48 или 100/65. Плагиатус пишет, что уникальность отличная, но возможен рерайт. Прохожу по ссылкам, сайты мне не знакомые. Это означает, что программа просто нашла совпадения словосочетаний, при этом плагиата нет (настройки 4/4), правильно?
Мой хлеб - короткие юридические посты на 700-900 знаков. Только копирайт, только из собственной головы. Уник 76-79, выделяются стандартные "юридические" обороты. Выбросить слова из песни невозможно, как невозможно придумать синоним фразе "свидетельство о рождении". Как-то так...
При таком раскладе мне добиться даже 80 уника почти нереально... не вижу ничего хорошего. А нужно 95. И все было прекрасно в старой версии. Лично у меня.
Такая же ерунда и с экономикой. Слава богу, я еще в состоянии писать никуда не глядя, но гаденыш-плагиатус черкает все термины. Учитывая, что без них никуда, то уникальность падает до 80%. И как с этим жить?
И что нам нужно сделать? Что не так? Мы считаем чистую математику. В вашем случае математика показывает, что ваш текст из такой сферы, в которой много устойчивых выражений. Заказчики же тоже понимают это?! Если не понимают - не работайте с ними.
Если заказчик будет проверять ваш текст с фразой 2 и шинглом 2 - и будет получать уникальность текста в 30% и будет требовать 100% - вы что будете делать? Приходить сюда и жаловаться на Плагиатус?
Я, наверное, нарвусь на бан сегодня... Пишу текст об алгоритме сокращения сотрудников на предприятии. На 3000 (450 слов) знаков, тычком пальца, насчитала приблизительно 40 словосочетаний, аналогов которым нельзя выдумать, ну никак. У меня такие тексты - через один. В них идет речь об установленных законом процедурах, где повторяются названия документов, государственных органов, законодательных актов документов, которые имеют стабильные названия, и не приемлют синонимайза. С текстами на 700-1000 знаков беда полная... Я еще не видела в своих работах цифр 65-68. Никогда. А последние два дня вижу. Со старой версией не было таких проблем. Граничная цифра никогда не падала ниже 86, даже если приходилось местами цитировать законодательство. Может это я одна такая, но что-то не так с новой версией...
Ради интереса проверил один и тот же текст 2 раза, выдало уникальность 91% и 88% соответственно. При этом при 91% указало, что низкая уникальность. Как-то неправильно.
Публикация комментариев и создание новых тем на форуме Адвего для текущего аккаунта ограничено. Подробная информация и связь с администрацией: https://advego.com/v2/support/ban/forum/1186



 Загружаются ответы...
Загружаются ответы...

